

OPTICharge
Abstract
Abstract
OPTICharge
Mentors:
Pooja M
Department of Mechanical Engineering
National Institute of Technology
Surathkal, Karnataka - 575025
Email: poojam.211me140@nitk.edu.in
Priyanshu Bhandari
Department of Electronics and Communication Engineering
National Institute of Technology
Surathkal, Karnataka - 575025
Email: priyanshubhandari.211ec136@nitk.edu.in
Mentees:
Rahul Sohan Gupta
Department of Mechanical Engineering
National Institute of Technology
Surathkal, Karnataka - 575025
Email: rahulgupta.221me244@nitk.edu.in
Suksha Kiran
Department of Mechanical Engineering
National Institute of Technology
Surathkal, Karnataka - 575025
Email: sukshakiran.221me153@nitk.edu.in
Shankaragouda
Department of Mining Engineering
National Institute of Technology
Surathkal, Karnataka - 575025
Email: shankar.221mn048@nitk.edu.in
Likith Raj A
Department of Mechanical Engineering
National Institute of Technology
Surathkal, Karnataka - 575025
Email: likithraja.221me328@nitk.edu.in
I. INTRODUCTION
Lithium-ion batteries play a pivotal role in various applications such as electrified transportation, clean power systems, and consumer electronics due to their high energy and power density. However, despite their promising characteristics, Li-ion batteries still face challenges related to limited capacity and long charging times. The capacity limitation is often attributed to factors such as battery chemistry, materials, and design.
The long charging time of Li-ion batteries is primarily influenced by the chosen charging strategy. There exists a delicate balance between achieving fast charging and preserving battery health. While aggressive current profiles can significantly reduce charging times, they may also induce detrimental effects on battery degradation, such as Solid Electrolyte Interphase (SEI) growth and Lithium plating deposition.
The most common charging procedure for Li-ion batteries is the Constant-Current Constant-Voltage (CC-CV) method, widely employed in the industry due to its reasonable performance and relatively straightforward implementation. However, despite its prevalence, this simple charging algorithm often relies on excessively conservative constraints. These constraints are designed to reduce the likelihood of safety hazards but come at the expense of longer charging times. As a result, the CC-CV method may not always represent the optimal charging policy for all scenarios.To address this limitation and improve charging efficiency, advanced battery management strategies have been developed. These strategies can generally be classified into two categories: model-based and model-free strategies.
A. Model-based strategies :
These approaches aim to find an optimal input trajectory for charging based on a predefined battery model. By utilizing mathematical models that describe the behavior of Li-ion batteries, such as electrochemical models or equivalent circuit models, model-based strategies can predict battery performance and optimize charging parameters accordingly. These strategies typically require accurate knowledge of the battery’s characteristics and may involve complex optimization algorithms to find the optimal charging profile.
B. Model-free strategies:
In contrast to model-based approaches, model-free strategies interact directly with the battery, treating it as the ”environment” in the context of Reinforcement Learning (RL). Instead of relying on explicit battery models, model-free strategies learn optimal charging policies through trial and error interactions with the battery. RL algorithms, such as Q-learning or policy gradient methods, are employed to iteratively adjust charging parameters based on observed outcomes and rewards. These strategies offer the advantage of adaptability and flexibility, as they can adapt to changing battery conditions and environments without relying on predefined models.
II. LITERATURE REVIEW
A. limitations of model based approach:
The exploitation of model-based charging procedures encounters several critical challenges that need to be addressed:
1) Model Uncertainties and Mismatches: Every battery model is subject to uncertainties and mismatches, affecting its accuracy in predicting battery behavior. Since the performance of the controller depends on the accuracy of the model, it is essential to conduct proper parameter identification procedures based on experimentally collected data. In the case of electrochemical models, which are commonly used for modeling Li-ion batteries, there are typically numerous parameters that need to be identified. This necessitates sophisticated experimental design techniques for parameter estimation to ensure accurate model representation.
2) Large-scale Optimization Problem: Electrochemical models often consist of a large number of states, describing various aspects of the battery’s behavior. However, in realistic scenarios, many of these states are not directly measurable, posing challenges for control implementation. Consequently, the presence of an observer, also known as a state estimator, is required to reconstruct the full state information from the available measurements. This leads to a large-scale optimization problem, which can be computationally intensive and challenging to solve in real-time applications.
3) Parameter Drift with Battery Age: Another challenge is the drift of model parameters as the battery ages. Over time, factors such as electrode degradation, electrolyte aging, and temperature variations can cause changes in the battery’s behavior, leading to parameter drift in the underlying electrochemical model. Despite this, existing modelbased strategies proposed in the literature typically do not consider the adaptability of the control strategy to variations in the model parameters. This lack of adaptability can result in suboptimal performance and reduced effectiveness of the charging procedure, particularly as the battery ages and its behavior deviates from the model predictions.
In summary, while model-based charging procedures offer theoretical insights and optimization capabilities based on accurate battery models, they face significant challenges related to uncertainties in model parameters, the complexity of optimization problems, and the drift of model parameters over time. Addressing these challenges requires advanced techniques for parameter identification, state estimation, and adaptive control, ensuring the robustness and effectiveness of model-based charging strategies in practical applications.
B. Reinforcement Learning
The challenges associated with model-based charging procedures can be effectively addressed by utilizing a charging procedure based on the Reinforcement Learning (RL) framework. In an RL framework, the charging process is viewed as a sequential decision-making problem, where an agent, representing the battery management system, interacts with the environment, represented by the battery itself. The agent takes specific actions, such as adjusting the applied current during charging, based on the current state of the environment, which includes parameters like charging time, battery temperature, and voltage. The objective of the agent is to learn an optimal control policy that maximizes a cumulative reward signal over time. The key advantage of RL-based charging procedures lies in the ability of the agent to learn directly from interactions with the environment, without relying on explicit battery models or parameter identifications. By observing the feedback (reward) from the environment and the current state, the agent can iteratively update its control policy to make better decisions over time. This section provides an overview of RL fundamentals, emphasizing key concepts such as state, action, reward, and the learning process through exploration and exploitation.
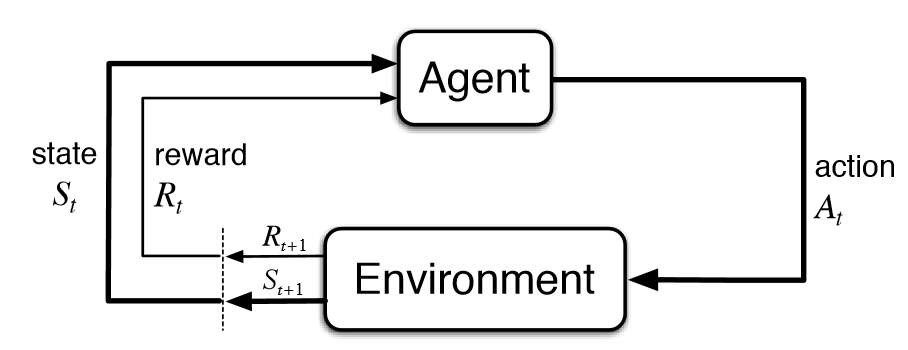
Fig. 1. Reinforcement learning [RL]
1) Agent: The agent is the entity that makes decisions and takes actions within an environment. Its role is to learn to perform tasks or achieve goals by interacting with the environment.
2) Environment: The environment is the external system or context in which the agent operates. It provides feedback to the agent based on its actions and influences the state transitions.
3) State: A state is a representation of the current situation or configuration of the environment. States are crucial for decision-making, as they determine the information available to the agent at a given moment.
4) Action: An action is the set of possible moves or decisions that an agent can take in a particular state. Actions influence the state transitions and, consequently, the rewards received by the agent.
5) Policy: A policy is a strategy or mapping from states to actions, representing the agent’s decision-making strategy. It guides the agent in choosing actions in different states to maximize expected cumulative rewards.
6) Reward: A reward is a numerical signal provided by the environment as feedback for the agent’s actions. Rewards serve as a reinforcement signal, guiding the agent to learn behaviors that lead to favorable outcomes.
7) Value Function: A value function estimates the expected cumulative future rewards associated with being in a particular state or taking a specific action. It helps the agent evaluate the desirability of different states or actions, aiding in decisionmaking.
8) Q-Value Function: The Q-value function represents the expected cumulative future rewards of taking a particular action in a given state. Q-values are crucial for determining the best action to take in a specific state and are often used in algorithms like Q-learning.
C. Lithium-ion Batteries
Lithium-ion batteries have become integral in energy storage, notably in EVs and portable electronics, due to their high energy density and light weight. However, efficiently charging these batteries while minimizing degradation poses a significant challenge. Balancing charging speed with battery health is crucial for maximizing their lifespan and performance. This delicate equilibrium requires careful management to prevent irreversible damage caused by factors like overcharging and high temperatures. Achieving optimal charging strategies is vital for realizing the full potential of lithium-ion batteries and advancing cleaner, more sustainable energy solutions.
D. Battery System Optimization
Understanding the challenges associated with battery systems is essential for developing effective optimization strategies. This section examines common challenges, including battery degradation, charge/discharge control, and the impact of varying operating conditions on overall system performance. An overview of current battery management systems is provided, emphasizing the limitations and areas where improvements are needed. This section sets the stage for discussing how RL can be integrated into existing BMS to overcome these limitations and optimize battery operations.
1) Prevailing DDPG Application: Deep Deterministic Policy Gradient (DDPG) is a dominant choice for SOC and temperature management in Battery Management Systems (BMS) using Reinforcement Learning (RL).
2) Alternate RL Algorithms: Other RL algorithms like Deep Q-Network (DQN) and Advantage Actor-Critic (A2C)have demonstrated potential in diverse control scenarios, suggesting potential applicability in BMS.
3) Research Gap and Opportunities: Despite the advancements in EV charging infrastructure optimization and BMS development, there remains a significant research gap in the integration of RL algorithms into BMS tailored for electric vehicle applications. Existing literature lacks dedicated comparative studies of RL algorithms within the context of BMS, specifically designed for electric vehicles. This gap presents an opportunity for the OPTICharge project to contribute valuable insights into the feasibility, effectiveness, and scalability of RL-based optimization techniques for EV charging infrastructure and battery management systems.
4) Objective of OptiCharge: This project aims to bridge this gap, offering a comprehensive evaluation of these RL algorithms for BMS in EV applications, providing crucial insights for the EV industry’s future Research and Development initiatives.
III. METHODOLOGY
A. Reinforcement Learning Framework
1) Actor-Critic Model: The reinforcement learning framework adopted in this study employs the Actor-Critic model, specifically the Deep Deterministic Policy Gradient (DDPG) algorithm. In the Actor-Critic paradigm, the actor component is responsible for selecting actions (in this case, charging current levels) based on the current state of the system (battery state and external temperature), while the critic component evaluates these actions and provides feedback to the actor. DDPG is particularly suitable for continuous control tasks, making it well-suited for optimizing charging current in lithium-ion batteries.

Fig. 2. Actor-critic model
2) State and Output Feedback: Two distinct approaches were utilized in this study to gather feedback from the battery:
a) Full State Feedback: This approach involves considering the complete state of the battery, including internal states such as electrode potentials and electrolyte concentrations. While comprehensive, this method may pose challenges in practical implementation due to the difficulty of accurately measuring internal battery states.
b) Output Feedback: In contrast, the output feedback approach relies on observable outputs such as voltage, temperature, and state of charge (SOC). While simpler to implement, this method may offer limited insight into the internal workings of the battery.
3) Adaptation to Battery Aging: A key advantage of the reinforcement learning framework employed in this study is its ability to adapt charging strategies as the battery ages. Lithium-ion batteries undergo changes in performance characteristics over time due to factors such as electrode degradation and electrolyte aging. By continuously learning from interactions with the battery, the RL model can adjust its charging policies to accommodate these changes, thereby ensuring optimal performance and longevity throughout the battery’s lifecycle. In summary, the reinforcement learning framework described in this study leverages the Actor-Critic model, utilizes both full state and output feedback approaches, and offers adaptability to battery aging. These features collectively enable the development of robust and effective charging strategies for lithium-ion batteries, maximizing performance while ensuring longevity and safety.
B. Electrochemical Battery Model
1) Model Description: The Doyle-Fuller-Newman (DFN) model serves as the foundation for simulating the electrochemical behavior of the battery in this study. The DFN model is a comprehensive physics-based model that describes the dynamic processes occurring within the battery, including the transport of ions and electrons, charge transfer kinetics, and electrode reactions. It considers various parameters such as temperature, state of charge (SOC), voltage, electrode potentials, and electrolyte properties, providing a detailed representation of the battery’s behavior under different operating conditions.

Fig. 3. DFN model schematic
2) Dimensionality Reduction: Given the complexity of the DFN model and the high dimensionality of its state space, dimensionality reduction techniques such as Principal Component Analysis (PCA) are employed to streamline the model for use in the reinforcement learning (RL) training process. PCA allows for the transformation of the original high-dimensional state space into a lower-dimensional feature space while preserving as much of the original information as possible. By reducing the dimensionality of the model, PCA simplifies the computational burden associated with RL training and enables more efficient exploration of the stateaction space. In practice, PCA identifies the principal components that capture the most significant variations in the data and projects the original state space onto these components. This process results in a reduced set of state variables that still adequately represent the battery’s behavior, facilitating faster and more effective learning by the RL agent. Additionally, PCA helps mitigate issues related to overfitting and improves the generalization capabilities of the RL model by focusing on the most relevant features of the battery’s electrochemical dynamics. In summary, the combination of the DFN model and dimensionality reduction techniques such as PCA provides a powerful framework for simulating and optimizing the behavior of lithium-ion batteries. By leveraging the detailed insights offered by the DFN model while streamlining its computational complexity through PCA, this approach enables the development of efficient and accurate RL-based charging strategies tailored to the specific characteristics of the battery system.
C. Fast-Charging problem
In battery management systems, achieving a balance between fast-charging and aging while ensuring safety constraints is crucial. The fast-charging objective involves reaching the final state of charge (SOC) in the shortest possible time without violating predefined constraints. The input current during charging is constrained by the hardware configuration of the battery charger, typically specified as:
-Imax ≤ I(t) ≤ 0
Here, negative current values represent charging the battery. To mitigate various degradation mechanisms within the battery, specific constraints must be adhered to throughout the charging process. Firstly, the cell temperature should not exceed a maximum threshold (Tmax) to limit the growth of the Solid Electrolyte Interphase (SEI) layer. Elevated temperatures accelerate SEI layer growth, which can degrade battery performance and longevity. Additionally, to prevent Lithium plating deposition, the sidereaction overpotential in the battery must be constrained to be positive. Lithium plating occurs when it becomes thermodynamically favorable for lithium to plate onto the surface of the negative electrode particles instead of intercalating. This phenomenon is particularly harmful as it can lead to the formation of dendrites, which may penetrate the separator and cause a short-circuit, compromising battery safety. It’s important to note that Lithium plating is exacerbated when the battery operates at low temperatures. Therefore, maintaining the battery within a suitable temperature range is crucial to mitigate this degradation mechanism and ensure the overall safety and longevity of the battery.
IV. RESULTS FOR OUTPUT FEEDBACK
A. Training
This section provides insights into the training and validation of the RL model under various conditions. It outlines the performance of the RL model compared to traditional charging methods such as Constant-Current Constant-Voltage (CCCV) and Constant Current Constant-Temperature ConstantVoltage (CC-CT-CV). The training process involves iteratively updating the RL model’s parameters based on interactions with the battery environment, while validation confirms the effectiveness of the learned charging policies.
1) Cumulative Return vs Episode Number: The cumulative return plotted against the episode number illustrates the learning progress of the reinforcement learning (RL) model over time. Each episode represents a complete charging scenario, helps assess the effectiveness of the RL model in regulating the charging process to prevent overcharging and ensure battery safety.4) Charging Time vs Episode Number: The relationship between charging time and episode number illustrates how the charging duration changes as the RL model learns and improves its charging strategy. A decrease in charging time over successive episodes indicates that the RL model is becoming more efficient at reaching the target state of charge while adhering to safety constraints. This metric is crucial for evaluating the practicality and effectiveness of the RL-based charging approach, as shorter charging times are generally desirable for enhancing user convenience and operational efficiency. and the cumulative return is a measure of the total reward obtained by the RL agent throughout the episode.

2) Temperature Violation vs Episode Number: This graph depicts the occurrence of temperature violations (instances where the battery temperature exceeds the specified maximum threshold) over the course of training episodes. It provides valuable information about the RL model’s ability to adhere to safety constraints during the charging process.

3) Voltage Violation vs Episode Number: This graph shows the occurrence of voltage violations (instances where the battery voltage exceeds the specified maximum threshold) throughout the training episodes. Voltage violations can indicate overcharging, which can lead to battery degradation and safety hazards. Monitoring voltage violations over time.

4)Charging Time vs Episode Number: The relationship between charging time and episode number illustrates how the charging duration changes as the RL model learns and improves its charging strategy. A decrease in charging time over successive episodes indicates that the RL model is becoming more efficient at reaching the target state of charge while adhering to safety constraints. This metric is crucial for evaluating the practicality and effectiveness of the RL-based charging approach, as shorter charging times are generally desirable for enhancing user convenience and operational efficiency.

B. Performance Metrics
The evaluation of the RL model’s performance is based on several key metrics. These include the charging time required to reach the target state of charge (SOC), adherence to safety constraints such as temperature and voltage limits throughout the charging process, and the model’s adaptability to parameter changes resulting from battery aging. By quantitatively assessing these metrics, the effectiveness and robustness of the RL approach can be comprehensively evaluated.
C. Comparison with Existing Methods
The results also include a comparison of the RL approach with existing conventional charging strategies. This comparison highlights the advantages of the RL model in terms of adaptability, efficiency, and safety. Specifically, the RL approach may demonstrate superior performance in adapting to parameter changes due to battery aging, optimizing charging time while ensuring safety constraints are met. By presenting these comparative analyses, the results emphasize the potential benefits of adopting RL-based charging strategies over traditional methods. Overall, the results section provides a comprehensive overview of the performance of the RL model in optimizing battery charging. Through empirical validation and comparative analyses, it demonstrates the efficacy of the RL approach in achieving faster, safer, and more adaptable charging strategies, ultimately contributing to the advancement of battery management systems for various applications.
1) Experimental setup:
It is well known that a proper experimental validation phase is required in order to assess the model accuracy in describing the cell behaviour. Within this context, the use of an accurate digital twin of the electrochemical cell is fundamental since it allows the researchers to test the proposed control algorithms directly in simulation, and therefore avoid time-consuming experiments on the real battery. In this section, we assess the level of confidence of the electrochemical thermal model presented in the previous section.

Fig. 4. Experimental setup
2) Model Results:
a) Current vs Time: This graph illustrates the current profile applied to the battery over time during model validation. It serves as a validation of the RL model’s ability to generate appropriate current profiles to achieve the desired state of charge (SoC) within specified constraints. By comparing the actual current profile with the target or optimal current profile, deviations can be analyzed, helping to assess the accuracy and effectiveness of the RL model in controlling the charging process.

b) Voltage vs Time: The voltage profile of the battery over time provides insights into the electrochemical behavior of the battery during charging. This graph serves as a validation of the RL model’s ability to regulate the charging voltage within safe limits while achieving the desired state of charge. Deviations from expected voltage levels can indicate inefficiencies or safety concerns in the charging process, which may require adjustments to the RL model’s control policies.

c) Temperature vs Time: Monitoring the temperature profile of the battery throughout the charging process is critical for assessing safety and preventing thermal runaway or degradation. This graph validates the RL model’s ability to control the battery temperature within specified limits, ensuring safe operation during charging. Deviations from the desired temperature range may indicate issues with the RL model’s control policies or the need for additional safety measures.

d) State of Charge (SoC) vs Time: The state of charge represents the amount of energy stored in the battery at a given time. This graph validates the RL model’s ability to accurately predict and control the SoC trajectory during charging. Comparing the predicted SoC profile generated by the RL model with the actual SoC measurements validates the effectiveness of the RL model in achieving the desired charging objectives. Discrepancies between predicted and actual SoC values may indicate inaccuracies in the RL model’s learning or limitations in the battery’s behavior modeling.

V. RESULTS FOR STATE FEEDBACK[PCA]
In the state feedback approach, the controller would directly measure internal parameters of the charging system, such as battery SoC, voltage, and current, and use this information to adjust the charging strategy in real-time to optimize charging efficiency, battery health, and user preferences. One of the main challenges of this approach is accurately measuring internal battery states in real-time. Electrode potentials and electrolyte concentrations are internal variables that are not directly observable without invasive or complex sensing techniques. Traditional methods for measuring these states, such as electrochemical sensors or spectroscopic analysis, may be expensive, require specialized equipment, or be impractical for continuous monitoring during charging. In summary, while considering the complete state of the battery offers significant benefits in terms of performance optimization and health management, practical implementation



VI. CONCLUSION
In this paper, we introduce a model-free deep reinforcement learning (RL) framework designed to tackle the challenge of fast-charging batteries while adhering to safety constraints. We utilize a detailed electrochemical model as the battery simulator to accurately represent the charging process. Among RL paradigms, we adopt the actor-critic scheme, specifically leveraging the Deep Deterministic Policy Gradient (DDPG) algorithm, renowned for its capability to handle continuous state and action spaces effectively.
To ensure compliance with safety constraints, we design a reward function that penalizes constraint violations, allowing the RL agent to learn and optimize charging strategies accordingly. Initially, we assume access to full state measurements
and compare the performance of a states-based RL algorithm against a reference governor approach, considered state-of-theart in the field. Subsequently, we consider a more realistic scenario where only output measurements, such as voltage, temperature, and state of charge (SOC), are available. Instead of relying on a state estimator, which can be challenging to design, we formulate an outputs-based configuration of the RL approach. This strategy is compared against a Constant-Current ConstantTemperature Constant-Voltage (CC-CT-CV) approach, widely regarded as a benchmark output feedback model-free approach.
Simulation results demonstrate that both RL formulations perform comparably to the state-of-the-art benchmarks, showcasing the effectiveness of RL in optimizing battery charging. However, the main advantage of RL lies in its adaptability. We analyze the outputs-based RL strategy’s performance in the presence of changing battery parameters mimicking aging.The results reveal that the RL approach maintains reasonable performance throughout the battery’s life, adapting to changes in the environment, whereas the CC-CT-CV approach eventually violates safety constraints as battery parameters change with aging. Our ongoing work involves experimental validation of the proposed framework using a hardware-in-the-loop testing environment with various objectives, aiming to further validate and refine the RL-based approach for real-world applications.
Vll. REFERENCES
1.Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Bar
2.Deep Reinforcement Learning with Python (DQN and variants) - Article
3.Reinforcement Learning for Optimal Control of Battery Charging
4.Creating an Environment for RL
5.RL — Reinforcement Learning Algorithms Comparison
VlII. ACKNOWLEDGEMENT
As executive members of IEEE NITK, we are extremely grateful for the opportunity to learn and work on this project under the prestigious name of IEEE NITK Student Chapter. We would like to extend our heartfelt thanks to IEEE for providing us with the necessary funds to complete this project successfully.
Report Information
Team Members
Team Members
Report Details
Created: March 23, 2024, 3:03 p.m.
Approved by: Anirudh Prabhakaran [CompSoc]
Approval date: None
Report Details
Created: March 23, 2024, 3:03 p.m.
Approved by: Anirudh Prabhakaran [CompSoc]
Approval date: None