

IMAGINE
Abstract
Abstract
Google meet link : https://meet.google.com/mfo-rjqf-dzh
Github Repository : https://github.com/Aj-Shaer07/C06-IMAGINE-EXPO
AIM
The aim of the IMAGINE project is to develop an autoencoder-based system that enhances and refines rough hand-drawn sketches, enabling accurate and realistic image generation using deep learning techniques.
INTRODUCTION
Human sketches are often rough, noisy, and incomplete, yet humans can easily understand the intended object or scene. Replicating this capability in machines requires combining multiple machine learning techniques that can understand structure, remove noise, and generate meaningful visual outputs.
The project takes a rough hand-drawn sketch as input and enhances it using a trained autoencoder model. The refined sketch is then combined with a user-provided text prompt and passed into a pretrained Stable Diffusion model to generate a realistic image.
The project combines computer vision, deep learning, generative AI, and natural language processing to build an intelligent sketch-to-image generation pipeline.
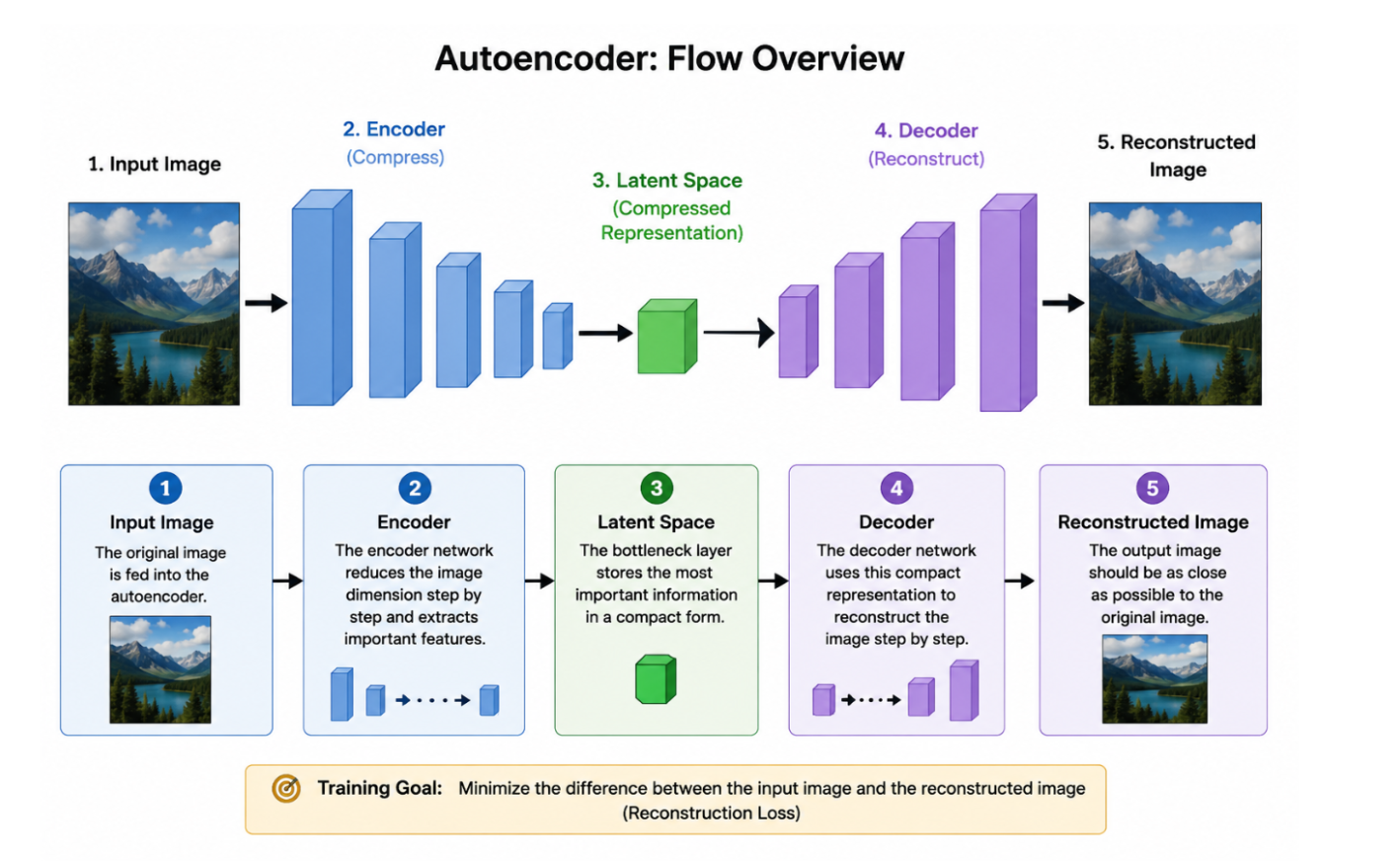
METHODOLOGY
Methodology – Denoising using Autoencoder
1. Data Collection and Preprocessing
The first step in the denoising process is preparing the dataset for training the autoencoder model. A collection of clean sketches or images is gathered and resized to a fixed dimension such as 128×128 or 256×256 pixels to maintain consistency during training. The pixel values are normalized so that the neural network can learn more efficiently.
To train the denoising autoencoder, artificial noise is intentionally added to the clean images. Different types of noise are used to simulate real-world distortions, including:
- Gaussian Noise
- Salt-and-Pepper Noise
- Blur Distortion
The noisy image acts as the input to the model, while the original clean image is used as the target output during training.

2. Autoencoder Architecture for Denoising
The denoising system is built using a Convolutional Autoencoder, which consists of two major components: the Encoder and the Decoder.
Encoder
The encoder extracts important visual features from the noisy image using:
- Convolutional Layers
- Activation Functions (ReLU)
- Pooling Layers
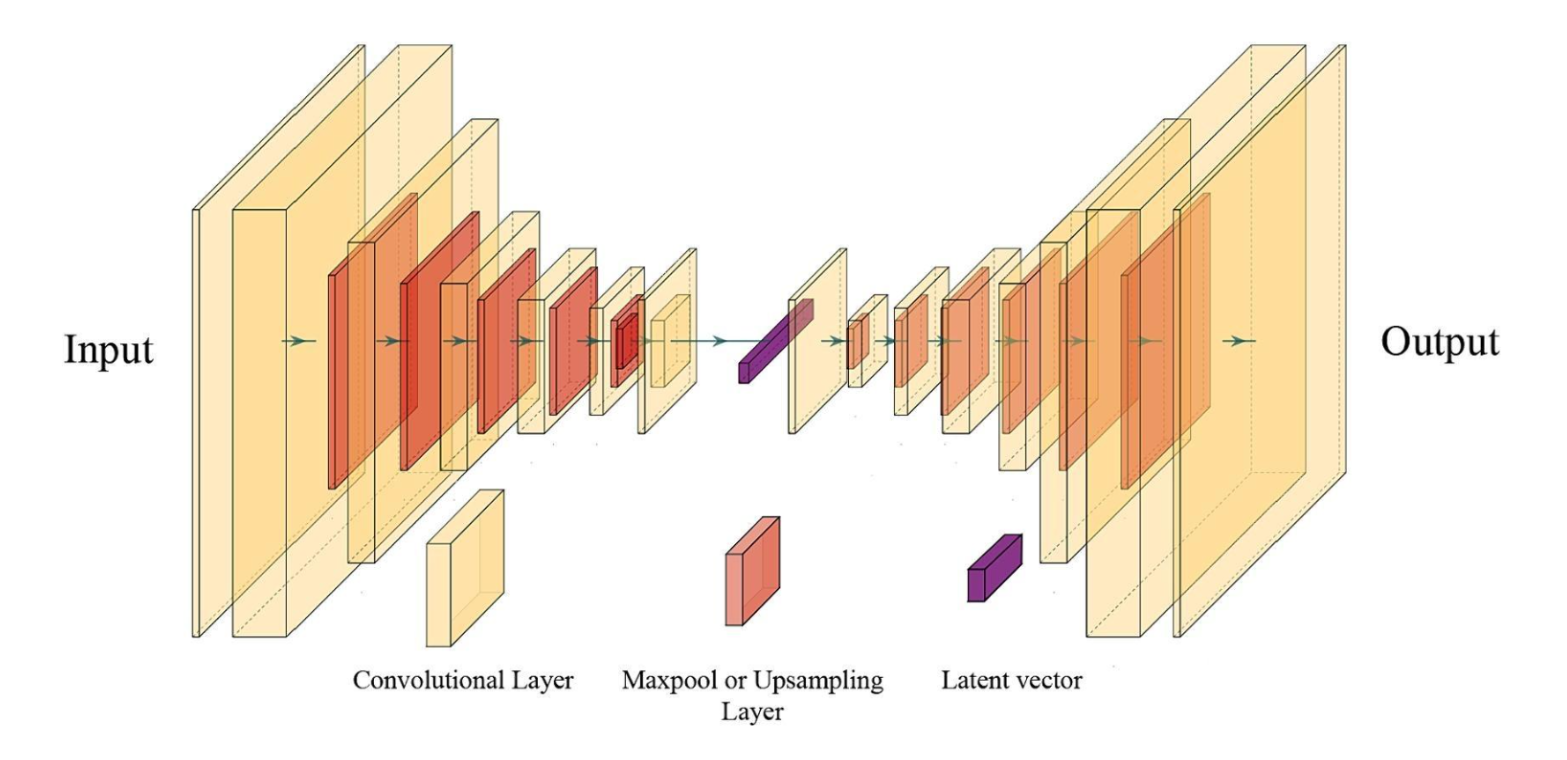
As the image passes through the encoder, unnecessary noisy information is gradually removed while important structural features such as edges, shapes, and patterns are preserved. The encoder converts the image into a compact latent representation that stores meaningful image information.
Decoder
The decoder reconstructs the image from the latent representation using:
- Upsampling Layers
- Transposed Convolutions
- Convolutional Layers
The decoder learns to recreate a cleaner version of the original image while preserving important image structures.
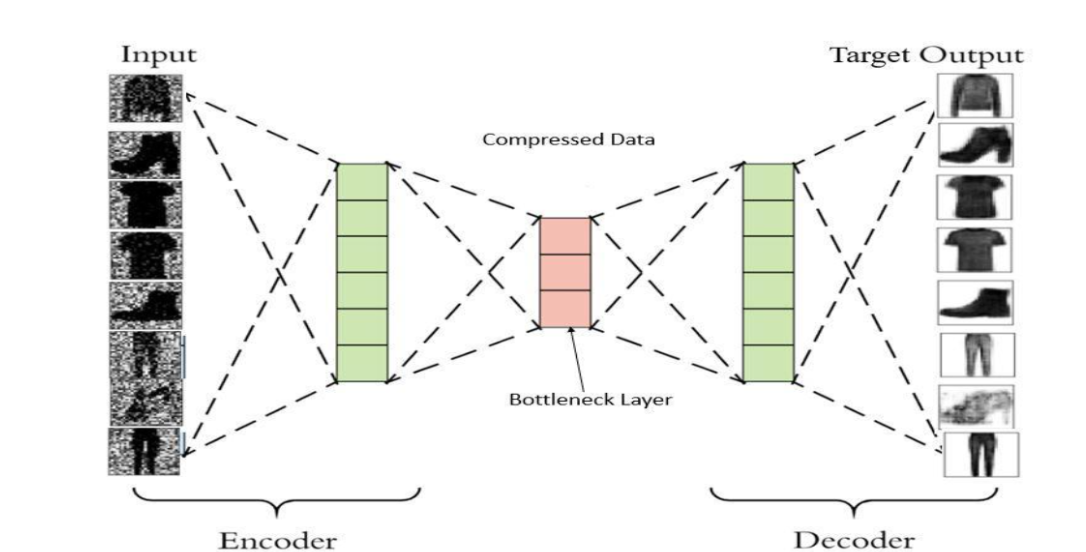
3. Denoising Process
During training:
A noisy image is provided as input to the autoencoder.
The encoder extracts meaningful structural information from the image.
The decoder reconstructs the image while suppressing noise.
The reconstructed output is compared with the original clean image.
Reconstruction loss is calculated and minimized using backpropagation.
The model gradually learns how to distinguish important image features from unwanted noise through repeated training iterations.
Loss Function
The reconstruction quality is measured using Mean Squared Error (MSE), which calculates the difference between:
- Original clean image
- Reconstructed output image
Lower loss values indicate better denoising performance.
4. Output
The trained autoencoder removes noise while preserving edges and important sketch details, producing cleaner and enhanced images for further processing.
RESULT

The image demonstrates an autoencoder-based denoising process using the Mona Lisa image. The noisy image contains distortions that reduce clarity, while the reconstructed image shows reduced noise and improved visual quality after denoising
The reconstructed image achieves a higher SSIM value, indicating better preservation of structural information after denoising. This demonstrates that the autoencoder effectively learns meaningful image representations and removes noise while maintaining essential image details.
Inference
The autoencoder-based denoising successfully improve image quality by removing noise and enhancing visual details. The denoising autoencoder effectively preserves important structural features while eliminating distortions from input sketches/images
Autoencoders are widely used to remove noise from images while preserving important details.
Applications include:
- Medical image enhancement
- CCTV footage cleaning
- Old photograph restoration
- Satellite image enhancement
CONCLUSION
The project successfully demonstrates the use of convolutional autoencoders for image denoising. The model effectively removes noise while preserving important image structures and visual quality. Evaluation using PSNR and SSIM confirms the effectiveness of the denoising process. The proposed system can be extended for advanced image restoration and computer vision applications.
REFERENCES
- TensorFlow Official Autoencoder Tutorial - Reference for understanding denoising autoencoders and reconstruction learning.
- Keras Official Blog – Building Autoencoders in Keras , Practical reference for encoder-decoder architectures and image reconstruction.
- Deep Learning Book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville - Reference for neural networks, representation learning, and autoencoders.
Report Information
Team Members
Team Members
Report Details
Created: May 12, 2026, 3:10 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 12, 2026, 3:10 p.m.
Approved by: None
Approval date: None